Главная страница>Блог>Статьи>Ценовая аналитика изнутри: что нужно знать о парсинге, сравнении цен и качестве данных
Статьи
4.09.2025
1 902
Ценовая аналитика изнутри: что нужно знать о парсинге, сравнении цен и качестве данных
Когда вы используете автоматизированные инструменты для анализа цен конкурентов, важно осознавать потенциальные риски, проблемы и опасности. Большинство из них связаны с качеством данных. В этом материале мы разберем, что такое качество данных, каким оно должно быть и как вам убедиться, что вы получаете точные, полные и актуальные данные о ценах конкурентов, на основе которых можно принимать взвешенные решения.
Бывший министр обороны США Дональд Рамсфелд сказал: «Есть известные известные, известные неизвестные, но самыми опасными являются неизвестные неизвестные — то, о чем мы даже не догадываемся, чего не знаем».
Вот ваши типичные неизвестные неизвестные, когда вы анализируете цены и ассортимент конкурентов через автоматизированные инструменты:
Вы получаете не все цены. Для понимания масштаба: большинство инструментов на рынке находят лишь 70–80% цен, которые нужно сравнивать.
Вы видите устаревшие цены. Большинство инструментов на самом деле не проводят сверку ежедневно, даже если в системе показана сегодняшняя дата обновления.
Система сравнивает не те товары, которые нужно. К примеру, не лучший аналог вашего товара. Это типичная история.
Хуже всего то, что вы не видите этих проблем, когда пользуетесь сервисом анализа цен конкурентов. Разберемся, как устроены сбор и сопоставление товаров на платформах ценовой аналитики, чтобы вы понимали, куда смотреть и как оценивать результат.оварів на платформах цінової аналітики, щоб ви розуміли, куди дивитися і як оцінювати результат.
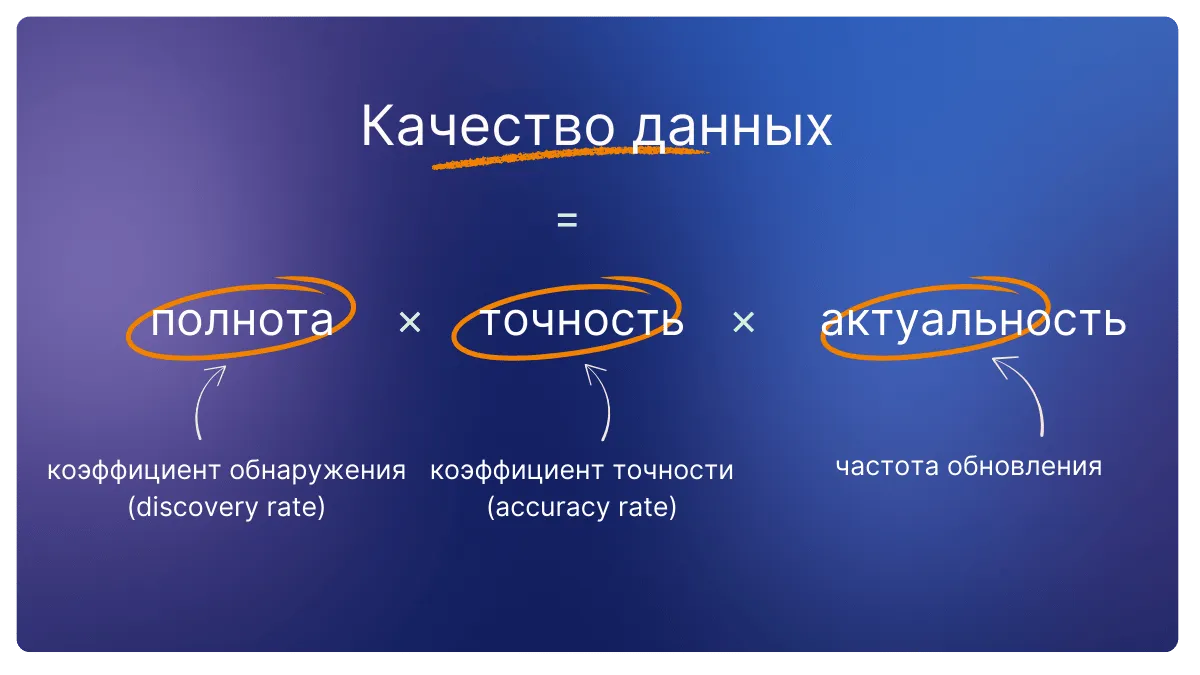
Качество данных состоит из трех ключевых аспектов: точности, полноты и актуальности.
В сфере ценовой аналитики их измеряют через коэффициент обнаружения, коэффициент точности и частоту обновлений.
Ключевые метрики качества данных
1. Коэффициент обнаружения
Коэффициент обнаружения (discovery rate) — это показатель эффективности системы мониторинга, отражающий, какую часть релевантных товаров она смогла найти и сопоставить среди всех товаров, имеющихся и в вашем ассортименте, и у конкурентов. Этот коэффициент помогает оценить полноту собранных данных.
Почему нужно иметь высокий коэффициент обнаружения:
Низкий discovery rate означает, что вы видите неполную картину рынка.
Вы можете пропустить ключевые товары конкурентов или новые позиции.
Решения о ценообразовании основаны на частичной информации.
Discovery rate Pricer24 — 98%, значительно выше среднего на рынке. Это результат очень тщательного подхода, который мы разрабатываем и совершенствуем уже пять лет. Узнайте больше по ссылке.
2. Коэффициент точности
Коэффициент точности (accuracy rate) — указывает на то, какую долю ваших товаров система корректно сопоставила с аналогичными товарами на сайтах конкурентов.
К примеру, если точность сопоставления составляет 95%, это означает 5% ошибок. В масштабе 100 000 офферов 5% ошибок — это 5000 офферов с неправильным сопоставлением.
Почему это критично:
Ошибочное сопоставление означает, что вы сравниваете «яблоки с апельсинами».
При этом вы не знаете, какие именно товары сопоставлены неправильно, потому что не просматриваете каждую пару, и в результате принимаете ошибочные ценовые решения.
Коэффициент точности Pricer24 — 99,5%, что обеспечивает максимально корректный анализ и уменьшает риски ошибок в ценообразовании. Узнайте больше по ссылке.
3. Частота обновления
От частоты обновления данных зависит, насколько актуальна информация, на которую вы опираетесь в принятии решений.
Почему это критично:
Цены и наличие товаров в e-commerce постоянно меняются. В динамических категориях (электроника, бытовая техника и др.) они могут меняться по несколько раз в день.
Пока вы принимаете решения на основе вчерашних цен, конкуренты уже продают дешевле.
Частота сбора данных в Pricer24:
Минимальная частота сбора данных — 1 раз в день для нединамичных категорий.
Нормальная частота сбора данных — 3–7 раз в день.
В случаях, когда высокая частота обновления критически важна, мы можем обновлять данные даже каждый час (а иногда и чаще).
Как происходит сбор данных из открытых источников и как работают парсеры
Все решения для сбора и анализа цен конкурентов применяют парсеры — специальные программы, которые копируют поведение человека-пользователя: загружают, «читают» веб-страницы или другие источники данных, находят, идентифицируют и собирают нужную информацию (например, цены, описание товаров, наличие).
Автоматически собирать открытые данные сложно, ведь парсер воспринимает их не так, как человек. Чтобы делать это качественно, необходимо использовать разные типы парсеров и методики сбора. Сейчас разберемся, какие именно.
Типы парсеров в Pricer24
Мы в Pricer24 применяем разные типы парсеров, чтобы обеспечить высокое качество данных:
парсеры категорий;
парсеры ссылок;
поисковые парсеры;
файл-парсеры.
Парсеры категорий собирают информацию со всей категории товаров на сайте. Такой парсер заходит в заданную категорию, проходит по всем страницам и собирает все товары.
Парсеры ссылок всегда настраивают индивидуально для конкретного клиента. Их основная задача — собирать данные по списку URL-адресов, которые клиент хочет отслеживать. У Pricer24 есть специальный модуль, в котором клиент самостоятельно задает нужные ему ссылки вручную. Такой подход позволяет ему самостоятельно управлять тем, какие именно товары или страницы он хочет мониторить. Это удобно для работы с выборочными SKU — например, при сравнении товаров-аналогов.
Файл-парсеры используют тогда, когда все данные поступают в одном массиве — это может быть интегрированный фид из вашей внутренней системы или цены поставщиков в формате файлов. В таком случае данные передаются скученно и для их сбора достаточно одного запроса. Мы настраиваем файл-парсер так, чтобы система правильно «считывала» структуру, ориентировалась в категориях и автоматически извлекала все нужные поля: названия, цены, наличие и т. д.
Важно: каждый парсер принадлежит исключительно одному клиенту, ни один другой клиент не имеет доступа к его данным. Наша система надежно защищает информацию своих пользователей и ваши чувствительные данные.
Источники данных, которые мы используем для анализа цен в Pricer24
Excel-файлы: в систему можно загружать прайсы вручную или автоматически — через синхронизацию с внешними источниками (FTP, Google Drive и т. п.).
B2B-порталы поставщиков: если клиент предоставляет нам логин и пароль для личного кабинета на портале поставщика, мы автоматизируем сбор прайсов, наличия товаров или других нужных данных. Следовательно, клиент получает полный контроль над ценообразованием и закупками в одном месте: видит цены конкурентов и поставщиков одновременно, что позволяет быстро принимать оптимальные решения без постоянного переключения между десятками вкладок.
Telegram-чаты: если поставщики клиента отправляют прайсы в формате сообщения в Telegram, мы можем настроить автоматическое считывание таких файлов. Pricer24 отслеживает обновления в чате, извлекает новые документы, обрабатывает их и обновляет данные в системе — без ручного вмешательства со стороны клиента.
Внутренние системы клиента: Pricer24 может интегрироваться с внутренними учетными системами клиента (например, 1С, SAP или другими ERP), чтобы регулярно получать данные об остатках на складах, закупочных ценах, РРЦ или др.
Таким образом открытые данные о конкурентах и внутренние данные клиента консолидируются в одной среде — в нашей системе.
Какие типы данных мы собираем
По умолчанию каждый парсер собирает информацию о ценах и наличии товаров.
Мы можем также собирать данные о промоакциях, условиях кредитования, рассрочке платежей, характеристиках товаров, условиях доставки, а также теги товаров и их рейтинги.
Кроме того, при необходимости, парсеры могут быть настроены на сбор других данных: объемов, цветов, дополнительных кодов, изображений, описаний и т. д.
Как мы контролируем актуальность данных
Каждый парсер в нашей системе имеет собственное расписание запуска, которое определяет, когда именно должны обновляться данные. К примеру, парсинг может стартовать в 7:00, 12:00 и 17:00 по киевскому времени (в настройках фиксируется часовой пояс — актуально для клиентов с широкой географией).
Для каждого запуска мы устанавливаем показатель Desire Parsing Time — это временное окно, в течение которого система должна успеть собрать данные (например, с 7:00 до 9:00) и Critical Parsing Time — максимально допустимое время для сбора данных. Если парсер не успевает обновить данные за желаемый промежуток, они получают статус «Outdated».
Если такое случается часто или система превышает максимальное допустимое время для парсинга, вмешиваются разработчики, которые исправляют эту проблему.
Очень мало провайдеров на рынке так делают: обычно их парсеры имеют одну логику и работают так, как со всеми клиентами.
Почему собирать открытые данные точно — сложно?
Парсинг цен конкурентов кажется простой задачей, ведь вся информация открыта и доступна на их сайтах. Однако между «данные есть в открытом доступе» и «данные можно автоматически собирать» лежит пропасть технических сложностей. Парсер видит страницу сайта не так, как человек. Он считывает код, а код сильно отличается от вида сайта для людей.
Процесс парсинга можно условно разделить на два этапа:
Пройти защиту и получить страницу сайта. Сайты активно борются с ботами с помощью капчи, проверок на «человечность», блокировки IP-адресов, динамического изменения структуры страниц. Парсер нужно «научить» собирать данные несмотря на эти мероприятия.
Найти на странице именно те данные, которые нужны. Даже получив страницу, найти конкретные данные среди тысяч строк кода — это как искать иголку в стоге сена. Та же цена может называться «price», «cost», «amount» или вообще прятаться в JavaScript-коде. Каждый сайт имеет уникальную структуру, которая может меняться регулярно, и к этому нужно подстраиваться.
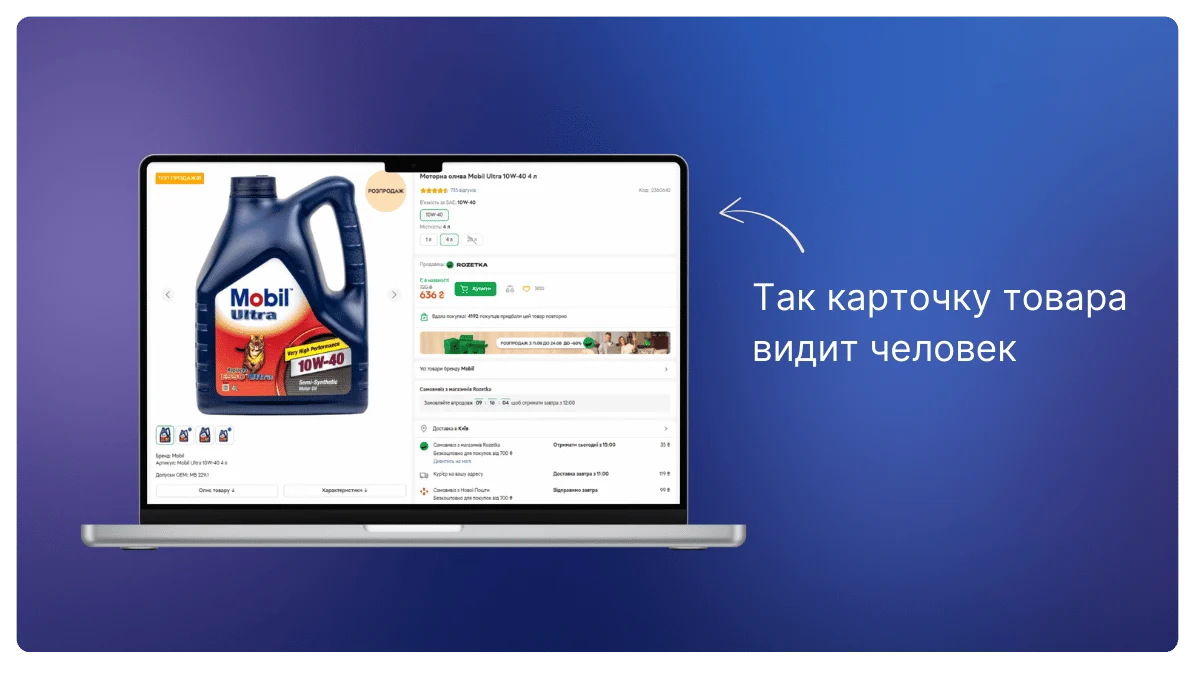
Рассмотрим на примере — возьмем обычную карточку товара на сайте Rozetka.ізьмемо звичайну картку товару на сайті Rozetka.
Когда вы как пользователь загружаете эту страницу, то видите всю необходимую информацию и характеристики.
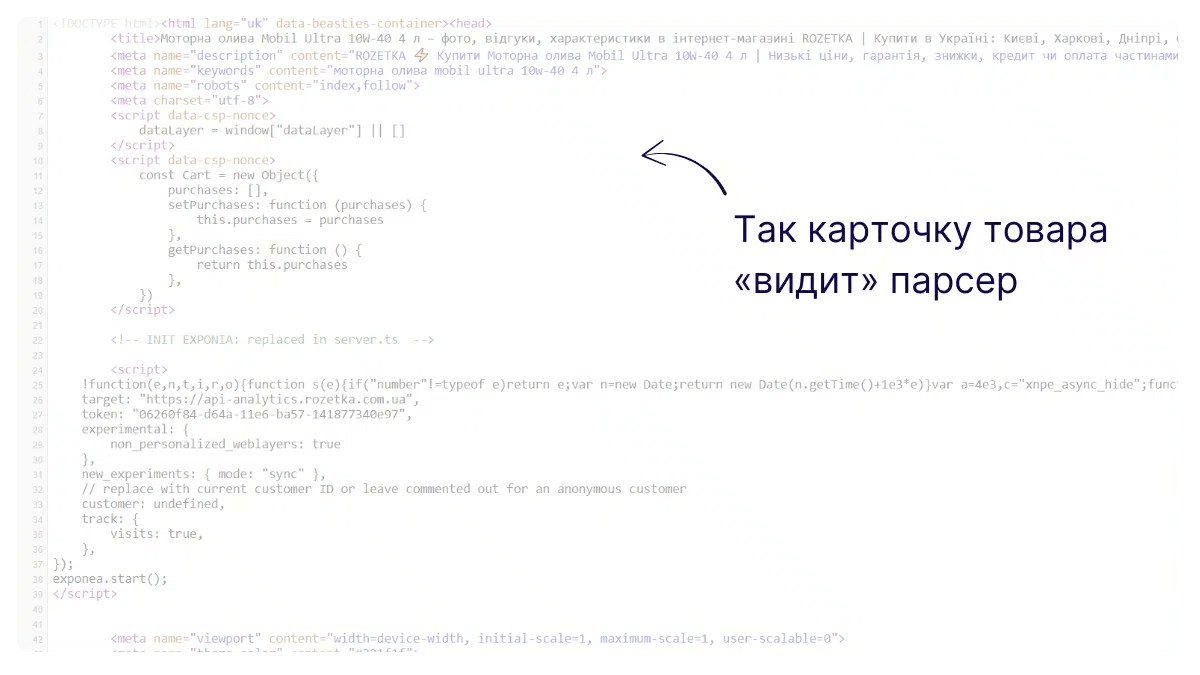
Если внимательно посмотреть на этот HTML-код, вы не найдете в нем ни названия товара, ни цены, ни рейтинга. Весь контент, который видит пользователь, фактически «невидимый» для парсера.
Это происходит потому, что многие современные интернет-магазины, кроме статического HTML-кода (который видят поисковые работы), используют динамический JavaScript, загружающий контент после открытия страницы.
То есть на самом деле, когда вы просматриваете страницу товара, сначала загружается «пустая» HTML-структура без названия товара, затем JavaScript выполняет дополнительные запросы на сервер, получает данные о товаре (название, цену, описание) и динамически вставляет их в страницу в красивом виде.
Как мы решаем эту проблему
Нам не нужно скачивать всю страницу, ведь чем меньше информации мы загружаем, тем быстрее это происходит (далее мы объясним, почему скорость важна). Мы находим алгоритм, который позволит просканировать так, чтобы собрать с него максимум информации, но при этом не собирать лишнее, потому что это увеличивает стоимость парсинга. Мы применяем различные стратегии в зависимости от технического задания.
Основной вызов в этой задаче— нестабильность структуры данных. Если сайт изменяет названия полей (например, «самовывоз» → «delivery»), парсер продолжает искать поле «самовывоз», не находит его и выдает ошибку.
Такие изменения на сайтах происходят постоянно и требуют регулярной донастройки парсеров. Меняется структура, названия полей. Каждое такое обновление может «сломать» парсер для конкретного сайта.
Что мы делаем:
постоянно мониторим работу парсеров и сразу видим уведомление от системы, когда что-то идет не так, как должно;
если парсер выдает ошибку, анализируем, что именно изменилось на сайте;
переписываем логику парсера под новую структуру;
тестируем и запускаем снова.
Чтобы обеспечить высокое качество данных, необходима постоянная техническая поддержка, а не разовая настройка.
Каждый сайт — это отдельная головоломка. С опытом у нас сформировалась условная «книга решений»: какие инструменты работают, как действовать с защитой, где обычно «прячутся» те или иные поля.
Вывод: то, что кажется простой задачей «скопировать данные с сайта», на самом деле требует постоянной работы целой команды разработчиков, которые ежедневно адаптируют сотни парсеров к изменениям в структурах данных разных источников.
Чем Pricer24 отличается от других сервисов для анализа цен?
Для каждого сайта мы кастомизируем свои базовые решения, что позволяет собирать данные максимально быстро — с той частотой, которую обещали клиенту.рел.
Мы не используем шаблонные решения. Каждый сайт анализируем отдельно, чтобы найти оптимальный способ получения максимума нужной информации при минимальном количестве запросов. Это означает более высокую скорость сбора данных и меньшую нагрузку на серверы.
У нас есть накопленный опыт и глубокое понимание различных технологий, используемых при создании сайтов, их систем защиты и особенностей структуры. И в зависимости от конкретного сайта выбираем подходящие инструменты для каждого случая.
Как происходит автоматизированный поиск товаров на сайтах конкурентов
Парсер скопировал все данные — и начинается выявление товаров-аналогов.
Важно понимать, как именно сервисы для мониторинга цен конкурентов находят среди тысяч позиций в чужих каталогах именно те товары, которые соответствуют вашим. Ведь это оказывает непосредственное влияние на discovery rate, то есть полноту данных.
Как большинство сервисов для анализа цен решают эту задачу?
Традиционный подход на рынке сервисов для мониторинга таков:
Подрядчик берет каталог клиента.
Ищет каждый товар на сайтах конкурентов.
Привязывает ссылку к найденным товарам.
Собирает цены по этим ссылкам.
Кажется, что все логично и просто. В чем же тут проблема?
В реальности товар, который у вас называется, например,
Ошейник для котов кожаный WAUDOG Glamour с QR паспортом без украшений XXS ширина 9 мм длина 22–30 см Голубой (32482),
у конкурента называется
Ошейник кошачий WAU DOG Glamour QR паспорт для маленьких котов (Blue).
Автоматика не найдет его по названию, и вы не будете знать, что у конкурента тоже есть этот товар.
У каждого конкурента — свои правила наименования. Чтобы качественно находить товары на десятках сайтов, нужно знать правила нейминга в каждой категории каждого сайта.
Наш подход — от общего к конкретному
Мы решаем эту задачу наоборот:
Когда начинаем сотрудничество с новым клиентом, он передает нам свой каталог и перечень сайтов для мониторинга.
Мы согласовываем техническое задание — в каких категориях эти товары нужно искать.
Создаем «Словарь брендов», где задаем соответствия брендов конкурентов к брендам в каталоге нашего клиента.
Создаем «Словарь товаров конкурента».
Регулярно собираем абсолютно все товары, которые есть в нужных категориях на сайтах конкурентов.
Ищем в каталоге клиента каждый собранный товар конкурента, потому что поиск на одном сайте более эффективный, чем на многих (проще запомнить структуру и ориентироваться в ней).
Именно на основе аналогов в каталоге клиента, а не конкурента, задаем соответствие.
Например, все товары, которые есть в категории «Ноутбуки» (категории конкурентов могут называться «Ноутбуки», «Лэптопы», и это прописано в техническом задании) на сайтах конкурентов, попадают в наш «Словарь», и далее мы к товару конкурента задаем соответствующий товар в каталоге клиента.
Если у клиента малый ассортимент в категории: например, 3 ноутбука против 3000 у конкурента, то собирать всю категорию конкурента неэффективно. Тогда мы ищем товары так, как это делают большинство сервисов, чтобы уменьшить ваши затраты.
Какие преимущества такой подход дает клиентам
Оптимизация и точность. Когда мы выполняем задачу сопоставления наоборот, то не должны изучать правила нейминга на всех сайтах конкурентов, а только знать логику нейминга своего клиента. Это означает более высокую точность сопоставления товаров.
Ежедневное выявление новинок. Другие сервисы могут не замечать новых товаров ваших конкурентов месяцами, а мы ежедневно анализируем категории конкурентов и выявляем все новые товары, которые в них появляются. Как только это происходит, система фиксирует новый товар, наша команда видит его в «Словаре», ищет аналог в каталоге клиента и, если он есть, делает связку. Это также позволяет получать актуальную информацию и осуществлять полный мониторинг, когда конкурент сознательно создает дубли товаров с более низкой ценой. Таким образом, discovery rate остается стабильно высоким.
Консистентность данных. Постоянное отслеживание изменений как в вашем каталоге, так и на сайтах конкурентов позволяет поддерживать данные в актуальном состоянии.
Поиск товаров с запутанными или неполными названиями
Мы ищем товары по комплексу параметров одновременно, причем набор этих параметров формируется в соответствии с вашим техническим заданием.
Например, для сравнения ноутбуков учитываются артикулы/партномера, названия товаров, а при неочевидном сопоставлении — общие технические характеристики: объем оперативной памяти (RAM), процессор (модель CPU, поколение, частота), тип видеокарты (GPU) и емкость накопителя, а также специфические характеристики, указывающие на комплектацию товара.
Для парфюмов сравнение может дополнительно включать такие признаки, как объем флакона, является ли продукт тестером, оригиналом, копией и т. д.
Так что, даже если продукт не совпадает по названию с вашим, мы все равно можем его найти.
Как осуществляется сопоставление товаров
Одна из главных составляющих качества любого сервиса аналитики цен конкурентов — правильное сопоставление товаров. В профессиональной терминологии этот процесс называют метчингом (от англ. matching). Именно он отвечает за точность данных — accuracy rate.
Часто ошибки в сопоставлении связаны с разными названиями товаров, разными способами указывать характеристики товара на двух сайтах или изменением фактического адреса карточки товара, когда система продолжает сравнивать ваш товар со старой ссылкой.
Сервисы для анализа цен применяют несколько подходов к сопоставлению товаров:
автоматический метчинг — быстрый, масштабируемый, но с высоким процентом погрешностей;
ручной метчинг — может быть достаточно точным, но является ресурсоемким;
AI-метчинг — сравнительно новый подход: сопоставление товаров происходит на основе моделей искусственного интеллекта, пытающихся «понять» данные и выделить названия товаров и описания.
Метчинг товаров в Pricer24
Мы применяем комбинацию трех подходов в самой выгодной для клиента пропорции. Запускаем несколько алгоритмов, каждый из которых сравнивает товары по разным параметрам: названию, артикулу, характеристикам, объему, позиционированию в категории и т. д., с целью найти как можно больше совпадений между двумя товарами.
Результаты каждого сопоставления проходят через систему оценки надежности.
Варианты, которые система оценки надежности определяет как «сомнительные», попадают в список на ручную проверку.
Если товар был сопоставлен по ошибке, человек фиксирует эту ошибку, и алгоритм ее больше не повторит. В результате он становится умнее с каждой проверкой.
Кроме того, у нас есть несколько уровней постфактум-проверок, что обеспечивает качественный контроль данных на протяжении всего сотрудничества с клиентом.
Этот подход позволяет нам достигать высокой точности даже в сложных случаях — и обеспечивать стабильное качество данных.
Что может пойти не так: случаи, когда проблемы с данными дорого стоят бизнесу
По нашим оценкам, в большинстве сервисов для анализа цен discovery rate в сложных категориях не превышает 50–60%, в простых категориях — достигает 80–85%. Средний показатель на рынке — примерно 70–75%. Это означает, что от четверти до половины конкурентных цен могут быть не учтены в анализе.
Вот примеры, которыми делились с нами клиенты, перешедшие на Pricer24 после неудачного опыта использования других платформ.
Антикейс 1. Неправильно сопоставленные товары = неправильные решения
Система автоматически сметчила ноутбук с Intel i3 у клиента с ноутбуком с Intel i5 у конкурента — одинаковая диагональ, одинаковый бренд, почти идентичные названия. Менеджер решил, что конкурент снизил цену, и тоже уменьшил ее. Но на самом деле конкурент продавал более дорогую модель.
Потери: –10% маржи за две недели.
Антикейс 2. Неполные данные = слепые зоны
Клиент получал отчеты из категории «Смарт-часы». Конкурент добавил в эту категорию новую линейку товаров, но категорийный менеджер не увидел появления более дешевых аналогов и продолжил продавать старую модель по завышенному ценнику.
Потери: –15% в продажах в категории в течение 2 недель, пока проблема не была выявлена вручную.
Антикейс 3. Устаревшие данные = запоздалые действия
Конкурент проводил акцию: популярные модели смартфонов по акционной цене на 48 часов. Но данные о ценах на этом сайте обновлялись 1 раз в 3 дня. Следствие: в отчете не было видно скидки, а значит — не было реакции.
Потери: упущенный момент для ценового ответа, уменьшение продаж по количеству SKU на 23% за неделю.
Вывод
Парсинг и метчинг в автоматизированной ценовой аналитике — это сложные многокомпонентные процессы. Качественный сбор, обработка и подготовка данных — это всегда результат кропотливой работы, накопленного опыта и отлаженных бизнес-процессов внутри команды сервиса для аналитики цен.
Каждый бизнес уникален, как отпечаток пальца. Поэтому логично, что и инструмент для аналитики должен быть адаптирован именно под вас.
Выбирая между «более простым» универсальным решением и кастомизированной системой ценовой аналитики, адаптирующейся под ваш бизнес, учитывайте свои бизнес-задачи и, самое главное, уровень качества данных, который вас устроит. От этого зависит ваша прибыльность и конкурентоспособность на рынке.
Pricer24 — это именно тот инструмент ценовой аналитики конкурентов, который точно отвечает вашим уникальным потребностям и дает стабильно высокое качество данных.
чтобы получить демонстрацию возможностей для вашего бизнеса
Політика конфіденційності
Ваша конфіденційність є дуже важливою для нас. Ми хочемо, щоб Ваша робота в Інтернет була максимально приємною і корисною, і Ви абсолютно спокійно використовували найширший спектр інформації, інструментів і можливостей, які пропонує Інтернет.
Особиста інформація Членів, зібраних під час реєстрації (або в будь-який інший час) переважно використовується для підготовки Продуктів або Послуг відповідно до Ваших потреб. Ваша інформація не буде передана або продана третім сторонам. Однак ми можемо частково розкривати особисту інформацію в особливих випадках, описаних у «Злагоді з розсилкою»
Які дані збираються на сайті
При добровільній реєстрації на отримання розсилки ви надсилаєте своє Ім’я та E-mail через форму реєстрації.
З якою метою збираються ці дані
Ім’я використовується для звернення особисто до вас, а ваш e-mail для надсилання вам листів розсилок, новин, корисних матеріалів, комерційних пропозицій.
Ваші ім’я та e-mail не передаються третім особам, за жодних умов крім випадків, пов’язаних з виконанням вимог законодавства.
Ви можете відмовитися від отримання листів розсилки та видалити з бази даних свої контактні дані у будь-який момент, клацнувши на посилання для відписки, присутнє в кожному листі.
Як ці дані використовуються
За допомогою цих даних збирається інформація про дії відвідувачів на сайті з метою покращення його змісту, покращення функціональних можливостей сайту та, як наслідок, створення якісного контенту та сервісів для відвідувачів.
В будь-який момент можна змінити налаштування свого браузера так, щоб браузер блокував усі файли або сповіщав про надсилання цих файлів. Зверніть увагу, що деякі функції та сервіси не зможуть працювати належним чином.
Як ці дані захищаються
Для захисту Вашої особистої інформації ми використовуємо різноманітні адміністративні, управлінські та технічні заходи безпеки. Наша Компанія дотримується різних міжнародних стандартів контролю, спрямованих на операції з особистою інформацією, які включають певні заходи контролю захисту інформації, зібраної в Інтернет.
Наших співробітників навчають розуміти та виконувати ці заходи контролю, вони ознайомлені з нашим повідомленням про конфіденційність, нормами та інструкціями.
Проте, незважаючи на те, що ми прагнемо убезпечити Вашу особисту інформацію, Ви також повинні вживати заходів, щоб захистити її.
Ми настійно рекомендуємо Вам вживати всіх можливих запобіжних заходів під час перебування в Інтернеті. Організовані нами послуги та веб-сайти передбачають заходи щодо захисту від витоку, несанкціонованого використання та зміни інформації, яку ми контролюємо. Незважаючи на те, що ми робимо все можливе, щоб забезпечити цілісність та безпеку своєї мережі та систем, ми не можемо гарантувати, що наші заходи безпеки запобіжать незаконному доступу до цієї інформації хакерів сторонніх організацій.
У разі зміни цієї політики конфіденційності ви зможете прочитати про ці зміни на цій сторінці або, в особливих випадках, отримати повідомлення на свій e-mail.