Strona Główna>Blog>Artykuły>Analityka cenowa od środka: co warto wiedzieć o parsowaniu, porównywaniu cen i jakości danych
Artykuły
14.09.2025
264
Analityka cenowa od środka: co warto wiedzieć o parsowaniu, porównywaniu cen i jakości danych
Korzystając z zautomatyzowanych narzędzi do analizy cen konkurencji, należy mieć świadomość potencjalnych ryzyk, problemów i zagrożeń. Większość z nich wiąże się z jakością danych. W tym materiale wyjaśnimy, czym jest jakość danych, jakie powinna spełniać kryteria oraz jak upewnić się, że otrzymujesz dokładne, kompletne i aktualne informacje o cenach konkurentów, na podstawie których można podejmować przemyślane decyzje.
Były sekretarz obrony USA Donald Rumsfeld powiedział: „Są rzeczy, o których wiemy, że je wiemy; są rzeczy, o których wiemy, że ich nie wiemy; ale najbardziej niebezpieczne są te, o których nie wiemy, że ich nie wiemy”.
Oto typowe „nieznane niewiadome”, gdy analizujesz ceny i asortyment konkurencji za pomocą narzędzi automatycznych:
Nie otrzymujesz wszystkich cen. Dla zobrazowania skali: większość narzędzi dostępnych na rynku znajduje jedynie 70–80% cen, które należałoby porównać.
Widzisz nieaktualne ceny. W rzeczywistości większość narzędzi nie przeprowadza weryfikacji codziennie, nawet jeśli w systemie widnieje dzisiejsza data aktualizacji.
System porównuje niewłaściwe produkty. Na przykład wybiera nieoptymalny odpowiednik dla Twojego towaru — to bardzo częsta sytuacja.
Najgorsze jest to, że korzystając z usługi analizy cen konkurencji, często nie widzisz tych problemów. Przyjrzyjmy się zatem, jak działa proces zbierania i dopasowywania produktów na platformach analityki cenowej, abyś wiedział, gdzie patrzeć i jak oceniać wyniki.
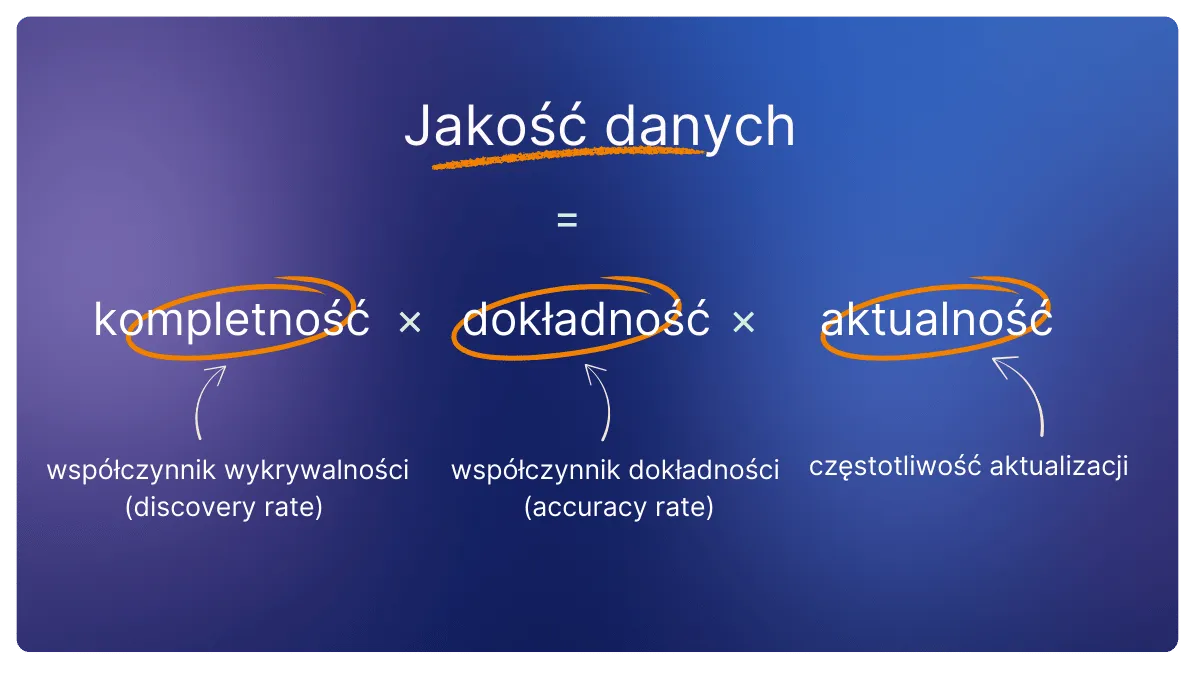
Jakość danych składa się z trzech kluczowych aspektów: dokładności, kompletności i aktualności.
W obszarze analityki cenowej mierzy się je za pomocą:
współczynnika wykrywalności (discovery rate),
współczynnika dokładności (accuracy rate),
częstotliwości aktualizacji.
Kluczowe metryki jakości danych
1. 1. Współczynnik wykrywalności
Współczynnik wykrywalności (discovery rate) to miara efektywności systemu monitoringu, która pokazuje, jaki odsetek istotnych produktów został odnaleziony i dopasowany spośród wszystkich pozycji dostępnych zarówno w Twoim asortymencie, jak i u konkurencji. Ten wskaźnik pozwala ocenić kompletność zebranych danych.
Dlaczego wysoki discovery rate ma znaczenie:
Niski współczynnik wykrywalności oznacza, że widzisz niepełny obraz rynku.
Możesz przeoczyć kluczowe produkty konkurencji lub nowe pozycje.
Decyzje cenowe są podejmowane na podstawie niepełnych informacji.
Discovery rate Pricer24 wynosi 98% — znacznie powyżej średniej rynkowej. To efekt skrupulatnego podejścia, które rozwijamy i udoskonalamy od ponad pięciu lat. Dowiedz się więcej.
2. Współczynnik dokładności
Współczynnik dokładności (accuracy rate) wskazuje, jaki odsetek Twoich produktów został prawidłowo dopasowany do odpowiedników na stronach konkurencji.
Przykład: jeśli dokładność dopasowania wynosi 95%, oznacza to 5% błędów. W skali 100 000 ofert to aż 5000 pozycji niepoprawnie dopasowanych.
Dlaczego to krytyczne:
Błędne dopasowanie oznacza, że porównujesz „jabłka z pomarańczami”.
Nie wiesz, które produkty zostały dopasowane nieprawidłowo, ponieważ nie przeglądasz każdej pary ręcznie. W efekcie podejmujesz błędne decyzje cenowe.
Współczynnik dokładności Pricer24 wynosi 99,5%, co zapewnia maksymalnie precyzyjną analizę i minimalizuje ryzyko błędów w polityce cenowej. Dowiedz się więcej.
3. Częstotliwość aktualizacji
Od częstotliwości aktualizacji danych zależy, jak bardzo aktualne są informacje, na których opierasz decyzje biznesowe.
Dlaczego to krytyczne:
Ceny i dostępność produktów w e-commerce zmieniają się nieustannie. W dynamicznych kategoriach (np. elektronika, AGD i inne) zmiany mogą następować nawet kilka razy dziennie.
Jeśli podejmujesz decyzje na podstawie wczorajszych danych, konkurencja może już sprzedawać taniej.
Częstotliwość zbierania danych w Pricer24:
Minimalna częstotliwość — raz dziennie dla kategorii o niskiej dynamice.
Standardowa częstotliwość — od 3 do 7 razy dziennie.
W przypadkach, gdy wysoka częstotliwość aktualizacji jest kluczowa, dane mogą być odświeżane nawet co godzinę (a czasem częściej).
Jak przebiega zbieranie danych ze źródeł otwartych i jak działają parsery
Wszystkie rozwiązania służące do zbierania i analizy cen konkurencji wykorzystują parsery — specjalne programy, które naśladują zachowanie użytkownika: ładują strony internetowe lub inne źródła danych, „czytają” ich zawartość, identyfikują potrzebne informacje (np. ceny, opisy produktów, dostępność) i automatycznie je gromadzą.
Zbieranie danych ze źródeł otwartych w sposób automatyczny jest trudne, ponieważ parser nie odbiera treści tak jak człowiek. Aby robić to skutecznie, konieczne jest zastosowanie różnych typów parserów oraz odpowiednich metod zbierania danych.
W dalszej części materiału omówimy, jakie dokładnie podejścia są stosowane.
Typy parserów w Pricer24
W Pricer24 stosujemy różne typy parserów, aby zapewnić wysoką jakość danych:
parsery kategorii,
parsery linków,
parsery wyszukiwawcze,
parsery plikowe.
Parsery kategorii zbierają informacje z całej kategorii produktów na stronie. Taki parser wchodzi do wskazanej kategorii, przechodzi przez wszystkie podstrony i gromadzi dane o wszystkich dostępnych produktach.
Parsery linków są konfigurowane indywidualnie dla każdego klienta. Ich głównym zadaniem jest zbieranie danych na podstawie listy adresów URL, które klient chce monitorować. W Pricer24 dostępny jest specjalny moduł, w którym klient może ręcznie wskazać konkretne linki. Dzięki temu ma pełną kontrolę nad tym, które produkty lub strony są objęte monitoringiem. To rozwiązanie szczególnie dobrze sprawdza się przy pracy z wybranymi SKU — np. podczas porównywania produktów analogicznych.
Parsery plikowe stosuje się wtedy, gdy dane są przekazywane w jednym zbiorczym pliku — może to być zintegrowany feed z wewnętrznego systemu lub cennik dostawcy w formacie plikowym. W takim przypadku wystarczy jedno zapytanie, aby pobrać cały zestaw danych. Parser plikowy jest konfigurowany tak, aby system prawidłowo odczytywał strukturę pliku, rozpoznawał kategorie i automatycznie wyciągał wszystkie potrzebne pola: nazwy, ceny, dostępność itd.
Ważne: każdy parser jest przypisany wyłącznie do jednego klienta. Żaden inny użytkownik nie ma dostępu do jego danych. Nasz system skutecznie chroni informacje użytkowników oraz Twoje wrażliwe dane.
Źródła danych wykorzystywane w analizie cen w Pricer24
Źródła otwarte: strony internetowe sklepów, marketplace’y, agregatory cen, aplikacje mobilne.
Pliki Excel: do systemu można wgrywać cenniki ręcznie lub automatycznie — poprzez synchronizację ze źródłami zewnętrznymi (FTP, Google Drive itp.).
Portale B2B dostawców: jeśli klient udostępni login i hasło do panelu dostawcy, automatyzujemy pobieranie cenników, dostępności produktów lub innych potrzebnych danych. Dzięki temu klient zyskuje pełną kontrolę nad cenami i zakupami w jednym miejscu — widzi jednocześnie ceny konkurencji i dostawców, co pozwala szybko podejmować optymalne decyzje bez konieczności przełączania się między dziesiątkami zakładek.
Systemy wewnętrzne klienta: Pricer24 może integrować się z wewnętrznymi systemami księgowymi klienta (np. 1С, SAP lub innymi ERP), aby regularnie pobierać dane o stanach magazynowych, cenach zakupu, cenach rekomendowanych (RRP) lub innych parametrach.
W ten sposób dane otwarte o konkurencji oraz dane wewnętrzne klienta są konsolidowane w jednym środowisku — w naszym systemie.
Jakie typy danych zbieramy
Standardowo każdy parser zbiera informacje o cenach i dostępności produktów.
Możemy również gromadzić dane o promocjach, warunkach kredytowania, płatnościach ratalnych, cechach produktów, warunkach dostawy, a także tagach i ocenach produktów.
Dodatkowo, w razie potrzeby, parsery mogą być skonfigurowane do zbierania innych danych: wolumenów, kolorów, dodatkowych kodów, zdjęć, opisów itp.
Jak kontrolujemy aktualność danych
Każdy parser w naszym systemie ma indywidualny harmonogram uruchamiania, który określa, kiedy dokładnie powinny być aktualizowane dane. Na przykład parsowanie może rozpoczynać się o 7:00, 12:00 i 17:00 czasu kijowskiego (w ustawieniach uwzględniana jest strefa czasowa — istotne dla klientów z szerokim zasięgiem geograficznym).
Dla każdego uruchomienia ustalamy wskaźnik Desire Parsing Time — to przedział czasowy, w którym system powinien zdążyć zebrać dane (np. od 7:00 do 9:00), oraz Critical Parsing Time — maksymalny dopuszczalny czas na zebranie danych. Jeśli parser nie zdąży zaktualizować danych w pożądanym przedziale, otrzymują one status „Outdated”.
Jeśli taka sytuacja powtarza się często lub system przekracza maksymalny czas parsowania, interweniują nasi programiści, którzy rozwiązują problem.
Bardzo niewielu dostawców na rynku stosuje takie podejście — zazwyczaj ich parsery działają według jednej logiki, wspólnej dla wszystkich klientów.
Dlaczego dokładne zbieranie danych otwartych jest trudne
Parsowanie cen konkurencji może wydawać się prostym zadaniem — przecież wszystkie informacje są publicznie dostępne na ich stronach. Jednak między „dane są dostępne” a „dane można automatycznie zebrać” istnieje przepaść pełna wyzwań technicznych.
Parser nie widzi strony tak jak człowiek. Odczytuje kod, który znacznie różni się od tego, co widzimy jako użytkownicy.
Proces parsowania można umownie podzielić na dwa etapy:
Pokonanie zabezpieczeń i pobranie strony. Strony aktywnie chronią się przed botami — stosują CAPTCHA, testy „human verification”, blokady adresów IP, dynamiczne zmiany struktury strony. Parser trzeba „nauczyć”, jak zbierać dane mimo tych zabezpieczeń.
Znalezienie właściwych danych na stronie. Nawet jeśli parser pobierze stronę, odnalezienie konkretnych danych wśród tysięcy linijek kodu to jak szukanie igły w stogu siana. Ta sama cena może być oznaczona jako „price”, „cost”, „amount” albo ukryta w kodzie JavaScript. Każda strona ma unikalną strukturę, która może się regularnie zmieniać — parser musi się do tego dostosowywać.
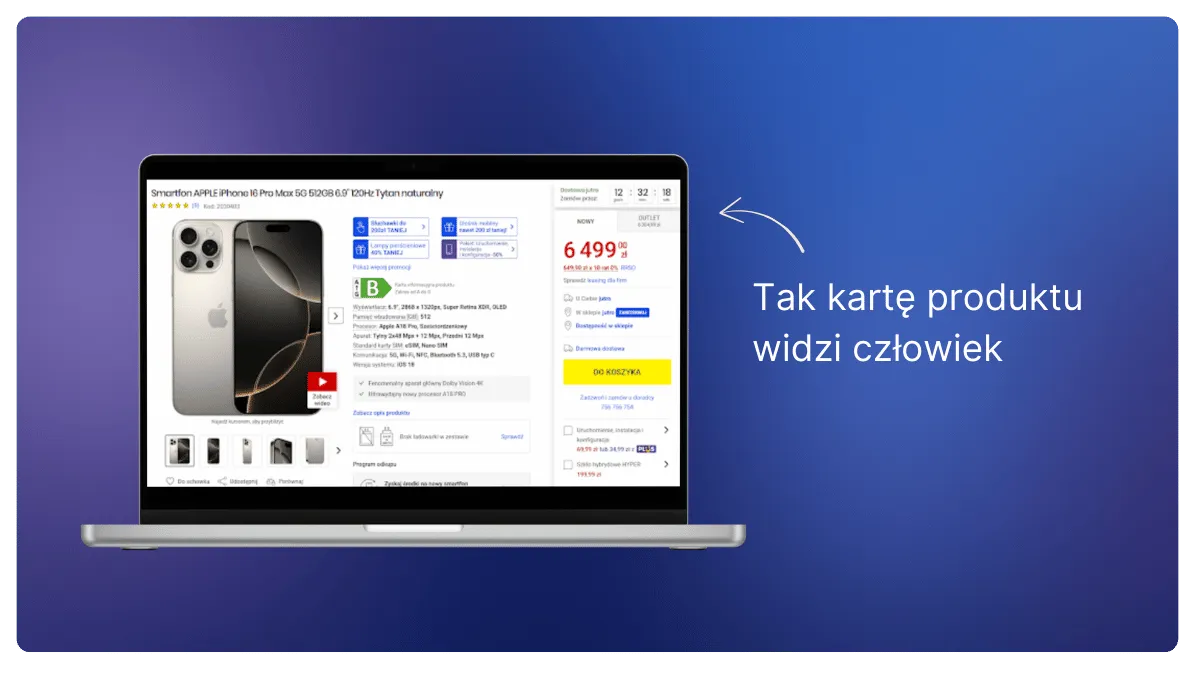
Przyjrzyjmy się temu na przykładzie — weźmy zwykłą kartę produktu na stronie Media Expert.
Kiedy jako użytkownik ładujesz tę stronę, widzisz wszystkie potrzebne informacje i parametry produktu.
A parser „widzi” taki kod HTML:
Jeśli dokładnie przyjrzysz się temu kodowi HTML, nie znajdziesz w nim ani nazwy produktu, ani ceny, ani oceny. Cała zawartość widoczna dla użytkownika jest w rzeczywistości „niewidoczna” dla parsera.
Dzieje się tak dlatego, że wiele nowoczesnych sklepów internetowych — oprócz statycznego kodu HTML (widocznego dla robotów wyszukiwarek) — wykorzystuje dynamiczny JavaScript, który ładuje treść dopiero po otwarciu strony.
W praktyce wygląda to tak: gdy przeglądasz stronę produktu, najpierw ładowana jest „pusta” struktura HTML bez nazwy produktu. Następnie JavaScript wykonuje dodatkowe zapytania do serwera, pobiera dane o produkcie (nazwę, cenę, opis) i dynamicznie wstawia je do strony w atrakcyjnej formie.
Jak rozwiązujemy ten problem
Nie musimy pobierać całej strony — im mniej danych ładujemy, tym szybciej przebiega proces (dalej wyjaśnimy, dlaczego szybkość ma znaczenie). Szukamy algorytmu, który pozwala zeskanować stronę w taki sposób, by zebrać z niej maksymalną ilość informacji, nie pobierając przy tym danych zbędnych, ponieważ zwiększają one koszt parsowania. Stosujemy różne strategie w zależności od specyfiki zadania technicznego.
Główne wyzwanie w tym procesie to niestabilność struktury danych. Jeśli strona zmienia nazwy pól (np. „odbiór osobisty” → „delivery”), parser nadal szuka pola „odbiór osobisty”, nie znajduje go i zgłasza błąd.
Takie zmiany na stronach następują regularnie i wymagają ciągłego dostosowywania parserów. Zmienia się struktura, nazwy pól — każda taka aktualizacja może „zepsuć” parser dla danego serwisu.
Co robimy:
stale monitorujemy działanie parserów i natychmiast otrzymujemy powiadomienia z systemu, gdy coś działa nieprawidłowo;
jeśli parser zgłasza błąd, analizujemy, co dokładnie zmieniło się na stronie;
przepisujemy logikę parsera zgodnie z nową strukturą;
testujemy i uruchamiamy ponownie.
Aby zapewnić wysoką jakość danych, niezbędne jest stałe wsparcie techniczne — nie jednorazowa konfiguracja.
Każda strona to osobna łamigłówka. Dzięki doświadczeniu stworzyliśmy swego rodzaju „księgę rozwiązań”: wiemy, które narzędzia działają, jak radzić sobie z zabezpieczeniami, gdzie zazwyczaj „ukrywają się” konkretne pola.
Wniosek: zadanie, które wydaje się proste — „skopiować dane ze strony” — w rzeczywistości wymaga ciągłej pracy całego zespołu programistów, którzy codziennie dostosowują setki parserów do zmian w strukturze danych różnych źródeł.
Czym Pricer24 różni się od innych usług analizy cen
Nie stosujemy gotowych, szablonowych rozwiązań. Każdą stronę analizujemy indywidualnie, aby znaleźć optymalny sposób pozyskania maksymalnej ilości potrzebnych danych przy minimalnej liczbie zapytań. Oznacza to wyższą szybkość zbierania informacji i mniejsze obciążenie serwerów.
Posiadamy bogate doświadczenie i dogłębną znajomość technologii wykorzystywanych przy tworzeniu stron internetowych, systemów zabezpieczeń oraz specyfiki ich struktury. W zależności od konkretnej witryny dobieramy odpowiednie narzędzia do każdego przypadku.
Dla każdej strony indywidualnie dostosowujemy nasze rozwiązania bazowe, co pozwala zbierać dane maksymalnie szybko — z taką częstotliwością, jaką obiecaliśmy klientowi.
Jak przebiega automatyczne wyszukiwanie produktów na stronach konkurencji
Parser skopiował wszystkie dane — i rozpoczyna się identyfikacja produktów odpowiedników.
Ważne jest, aby zrozumieć, jak dokładnie działają systemy monitorowania cen konkurencji, które spośród tysięcy pozycji w obcych katalogach potrafią znaleźć właśnie te produkty, które odpowiadają Twoim. To bezpośrednio wpływa na discovery rate, czyli kompletność danych.
Jak większość usług analizy cen realizuje to zadanie?
Typowe podejście na rynku monitoringu cen wygląda następująco:
Wykonawca otrzymuje katalog klienta.
Szuka każdego produktu na stronach konkurencji.
Przypisuje linki do znalezionych pozycji.
Zbiera ceny na podstawie tych linków.
Brzmi logicznie i prosto. Gdzie więc tkwi problem?
W rzeczywistości produkt, który u Ciebie nazywa się:
Obroża skórzana dla kota WAUDOG Glamour z paszportem QR, bez ozdób, XXS, szerokość 9 mm, długość 22–30 cm, niebieska (32482),
u konkurenta może mieć nazwę:
Obroża dla kota WAU DOG Glamour QR paszport dla małych kotów (Blue).
Automatyczne wyszukiwanie nie znajdzie go po nazwie — i nie dowiesz się, że konkurent również oferuje ten produkt.
Każdy konkurent stosuje własne zasady nazewnictwa. Aby skutecznie identyfikować produkty na dziesiątkach stron, trzeba znać reguły namingowe w każdej kategorii i dla każdego sklepu.
Nasze podejście — od ogółu do szczegółu
Realizujemy to zadanie odwrotnie niż większość usług:
Gdy rozpoczynamy współpracę z nowym klientem, otrzymujemy jego katalog oraz listę stron do monitorowania.
Uzgadniamy specyfikację techniczną — w jakich kategoriach należy szukać tych produktów.
Tworzymy „Słownik marek”, w którym definiujemy odpowiedniki marek konkurencji względem marek z katalogu klienta.
Tworzymy „Słownik produktów konkurencji”.
Regularnie zbieramy wszystkie produkty dostępne w wybranych kategoriach na stronach konkurencji.
Każdy zebrany produkt konkurencji porównujemy z katalogiem klienta — ponieważ wyszukiwanie na jednej stronie jest bardziej efektywne niż na wielu (łatwiej zapamiętać strukturę i poruszać się po niej).
Odpowiedniki definiujemy na podstawie katalogu klienta, a nie konkurencji. Na przykład: wszystkie produkty z kategorii „Laptopy” (u konkurencji mogą to być „Laptopy”, „Notebooki” — zgodnie z opisem w specyfikacji technicznej) trafiają do naszego „Słownika”, a następnie przypisujemy im odpowiednie produkty z katalogu klienta.
Jeśli klient ma niewielki asortyment w danej kategorii — np. 3 laptopy wobec 3000 u konkurenta — zbieranie całej kategorii konkurencji jest nieefektywne. Wówczas stosujemy podejście większości usług, aby ograniczyć koszty klienta.
Jakie korzyści daje klientom takie podejście
Optymalizacja i precyzja. Gdy realizujemy zadanie dopasowania „odwrotnie”, nie musimy analizować zasad nazewnictwa na wszystkich stronach konkurencji — wystarczy znać logikę nazewnictwa klienta. To przekłada się na wyższą precyzję dopasowania produktów.
Codzienne wykrywanie nowości. Inne systemy mogą nie zauważać nowych produktów konkurencji przez wiele tygodni, a my codziennie analizujemy kategorie konkurentów i identyfikujemy wszystkie nowe pozycje. Gdy tylko pojawi się nowy produkt, system go rejestruje, nasz zespół widzi go w „Słowniku”, szuka odpowiednika w katalogu klienta i — jeśli taki istnieje — tworzy powiązanie. Dzięki temu klient otrzymuje aktualne dane i pełny monitoring, nawet gdy konkurent celowo tworzy duplikaty produktów z niższą ceną. Discovery rate pozostaje stale wysoki.
Spójność danych. Stałe śledzenie zmian zarówno w katalogu klienta, jak i na stronach konkurencji pozwala utrzymywać dane w aktualnym i spójnym stanie.
Wyszukiwanie produktów o niejednoznacznych lub niepełnych nazwach
Szukamy produktów na podstawie zestawu parametrów jednocześnie — a zestaw ten jest tworzony zgodnie z Twoją specyfikacją techniczną.
Na przykład, przy porównywaniu laptopów uwzględniamy: numery katalogowe / part numbery, nazwy produktów, ogólne parametry techniczne w przypadku nieoczywistego dopasowania: pojemność pamięci RAM, model, generacja i częstotliwość procesora (CPU), typ karty graficznej (GPU), pojemność dysku, oraz specyficzne cechy wskazujące na konfigurację produktu.
W przypadku perfum do porównania mogą dodatkowo zostać uwzględnione takie cechy, jak: pojemność flakonu, czy produkt jest testerem, oryginałem, kopią itp.
Dzięki temu, nawet jeśli nazwa produktu nie pokrywa się z Twoją, jesteśmy w stanie go odnaleźć.
Jak odbywa się dopasowanie produktów
Jednym z kluczowych elementów jakości każdego systemu analizy cen konkurencji jest prawidłowe dopasowanie produktów. W profesjonalnej terminologii ten proces nazywany jest matchingiem. To właśnie on odpowiada za dokładność danych — accuracy rate.
Błędy w dopasowaniu często wynikają z:
różnych nazw produktów,
odmiennych sposobów prezentacji parametrów na dwóch stronach,
zmiany faktycznego adresu strony produktu, gdy system nadal porównuje go z nieaktualnym linkiem.
Systemy analizy cen stosują kilka podejść do dopasowania produktów:
Automatyczny matching — szybki i skalowalny, ale obarczony wysokim ryzykiem błędów.
Ręczny matching — może być bardzo dokładny, lecz wymaga dużych zasobów.
Matching oparty na AI — stosunkowo nowe podejście, w którym dopasowanie odbywa się na podstawie modeli sztucznej inteligencji, próbujących „zrozumieć” dane i wyodrębnić nazwy oraz opisy produktów.
Matching produktów w Pricer24
Stosujemy kombinację trzech podejść w proporcji najbardziej korzystnej dla klienta. Uruchamiamy kilka algorytmów, z których każdy porównuje produkty według różnych parametrów: nazwy, numeru katalogowego, cech technicznych, pojemności, pozycji w kategorii itd. — aby znaleźć jak najwięcej trafnych dopasowań między dwoma produktami.
Wyniki każdego dopasowania przechodzą przez system oceny wiarygodności.
Warianty uznane przez system za „wątpliwe” trafiają na listę do ręcznej weryfikacji.
Jeśli produkt został dopasowany błędnie, osoba odpowiedzialna rejestruje ten błąd, a algorytm nie powtórzy go w przyszłości. Dzięki temu staje się coraz „inteligentniejszy” z każdą kolejną korektą.
Dodatkowo wdrożyliśmy kilka poziomów kontroli post-factum, co zapewnia wysoką jakość danych przez cały okres współpracy z klientem.
Takie podejście pozwala nam osiągać wysoką precyzję nawet w trudnych przypadkach — i gwarantować stabilną jakość danych.
Co może pójść nie tak: przypadki, w których problemy z danymi kosztują biznes
Według naszych szacunków, w większości systemów analizy cen discovery rate w trudnych kategoriach nie przekracza 50–60%, a w prostszych sięga 80–85%. Średni wskaźnik na rynku to około 70–75%. Oznacza to, że od jednej czwartej do połowy cen konkurencji może nie zostać uwzględniona w analizie.
Oto przykłady, którymi podzielili się z nami klienci, którzy przeszli na Pricer24 po nieudanych doświadczeniach z innymi platformami:
System automatycznie dopasował laptop z procesorem Intel i3 u klienta do modelu z Intel i5 u konkurenta — ta sama przekątna, ta sama marka, niemal identyczna nazwa. Menedżer uznał, że konkurent obniżył cenę, i również ją zredukował. W rzeczywistości konkurent oferował droższy model.
Straty: –10% marży w ciągu dwóch tygodni.
Antyprzypadek 2. Niepełne dane = martwe strefy
Klient otrzymywał raporty z kategorii „Smartwatche”. Konkurent dodał nową linię tańszych modeli, ale menedżer kategorii nie zauważył ich pojawienia się i nadal sprzedawał starszy model po zawyżonej cenie.
Straty: –15% sprzedaży w kategorii w ciągu 2 tygodni, zanim problem został wykryty ręcznie.
Antyprzypadek 3. Przestarzałe dane = spóźnione reakcje
Konkurent przeprowadził promocję: popularne modele smartfonów w obniżonej cenie przez 48 godzin. Ale dane z tej strony były aktualizowane raz na 3 dni. W efekcie raport nie uwzględnił obniżki, więc nie było żadnej reakcji.
Straty: utracona szansa na reakcję cenową, spadek sprzedaży o 23% liczby SKU w ciągu tygodnia.
Wnioski
Parsing i matching w zautomatyzowanej analizie cen to złożone, wieloetapowe procesy. Wysokiej jakości pozyskiwanie, przetwarzanie i przygotowanie danych to zawsze efekt skrupulatnej pracy, zdobytego doświadczenia i dobrze zorganizowanych procesów biznesowych wewnątrz zespołu analitycznego.
Każdy biznes jest unikalny — jak odcisk palca. Dlatego narzędzie do analizy cen powinno być dostosowane właśnie do Twoich potrzeb.
Wybierając między „prostszym”, uniwersalnym rozwiązaniem a spersonalizowanym systemem analityki cenowej, który dopasowuje się do Twojego modelu biznesowego, warto uwzględnić konkretne cele oraz — co najważniejsze — poziom jakości danych, który Cię satysfakcjonuje. To właśnie od tego zależy Twoja rentowność i konkurencyjność na rynku.
Pricer24 to narzędzie analizy cen konkurencji, które precyzyjnie odpowiada na Twoje indywidualne potrzeby i zapewnia stabilnie wysoką jakość danych.
Wyślij zgłoszenie, aby zobaczyć naszą usługę w akcji i upewnić się, że spełnia twoje potrzeby
Privacy policy
Your privacy is very important to us. We want your work on the Internet to be as pleasant and useful as possible, and you quite calmly used the broadest range of information, tools and opportunities that the Internet offers.
The personal information of the Members collected at the time of registration (or at any other time) is mainly used to prepare the Products or Services in accordance with your needs. Your information will not be transferred or sold to third parties. However, we may partially disclose personal information in special cases described in the „Consent with the mailing”
What data is collected on the site
At voluntary registration on reception of dispatch you send the Name and E-mail through the registration form.
What is the purpose of this data?
The name is used to contact you personally, and your e-mail for sending you mailings of newsletters, news, useful materials, commercial offers.
Your name and e-mail are not transferred to third parties, under any circumstances, except for cases related to the compliance with the requirements of the law.
You can refuse to receive mailing letters and remove your contact information from the database at any time by clicking on the unsubscribe link present in each letter.
How this data is used
With the help of these data, information on the actions of visitors on the site is collected in order to improve its content, improve the functionality of the site and, as a result, create high-quality content and services for visitors.
You can change your browser settings at any time so that the browser blocks all files or notifies you about sending these files. Note at the same time that some functions and services will not be able to work properly.
How this data is protected
To protect your personal information, we use a variety of administrative, management and technical security measures. Our Company adheres to various international control standards aimed at transactions with personal information, which include certain control measures to protect information collected on the Internet.
Our employees are trained to understand and follow these control measures, they are familiarized with our Privacy Notice, regulations and instructions.
Nevertheless, despite the fact that we are trying to protect your personal information, you too must take measures to protect it.
We strongly recommend that you take all possible precautions while on the Internet. The services and websites that we organize include measures to protect against leakage, unauthorized use and alteration of the information we control. Despite the fact that we are doing everything possible to ensure the integrity and security of our network and systems, we can not guarantee that our security measures will prevent illegal access to this information by hackers from outside organizations.
If this privacy policy is changed, you will be able to read about these changes on this page or, in special cases, receive a notification on your e-mail.