Main page>Blog>Articles>Price Analytics from the Inside: What You Need to Know about Parsing, Price Comparison, and Data Quality
Articles
14.09.2025
1,125
Price Analytics from the Inside: What You Need to Know about Parsing, Price Comparison, and Data Quality
When you use automated tools to analyze competitors’ prices, it’s important to be aware of potential risks and pitfalls. Most are related to data quality. In this article, we break down what data quality is, and how you can make sure you are getting accurate, complete, and up-to-date competitor price data with which you can make well‑informed decisions.
Former U.S. Secretary of Defense Donald Rumsfeld once said: “Reports that say that something hasn’t happened are always interesting to me, because as we know, there are known knowns; there are things we know we know. We also know there are known unknowns; that is to say we know there are some things we do not know. But there are also unknown unknowns — the ones we don’t know we don’t know. … it is the latter category that tend to be the difficult ones.”
In reality, the unknown unknowns “tend to be the difficult ones” not only in the defense sector. Here are typical unknown unknowns when analyzing competitors’ prices and assortments using automated tools:
You aren’t seeing all the prices. To understand the scale: most price analytics tools only find prices for 70–80% of products available from competitors.
You’re seeing outdated prices. Most tools do not actually perform daily checks, even if the system shows it was last updated today.
The system is comparing the wrong products. It’s common for price analytics tools to not find the best product matches.
The worst part is that you won’t be aware of these problems when using most price analytics services.
Let’s figure out how product collection and matching work on most price analytics platforms. This way, you’ll know what to focus on, which questions to ask your provider, and how to make sense of their answers.
Data quality consists of three key aspects: accuracy, completeness, and timeliness.
In the field of price analytics, these are measured through the discovery rate, the accuracy rate, and the update frequency.
Key Data Quality Metrics
1. Discovery Rate
The discovery rate indicates the effectiveness of a monitoring system, showing what share of relevant products the system is able to find and match among all products available both in your assortment and in competitors’ assortments. This metric helps you assess the completeness of collected data.
Why you need a high discovery rate:
To get a full picture of the market
To not miss key products or new items from competitors
To make pricing decisions based on complete information
The accuracy rate indicates what share of your products the system has correctly matched with equivalent products on competitors’ websites.
For example, if the matching accuracy is 95%, this means a 5% error rate. On a scale of 100,000 offers, a 5% error rate equals 5,000 offers matched incorrectly.
Why this is critical:
Incorrect matching means you are comparing apples to oranges.
You cannot know which specific products have been matched incorrectly, since you cannot review every pair. As a result, you may make flawed pricing decisions.
The frequency of data updates determines how current the information is that you rely on when making decisions.
Why this is critical:
Prices and product availability in e‑commerce are constantly changing. In dynamic categories (electronics, household appliances, and others), prices can change several times a day.
While you are making decisions based on yesterday’s prices, competitors may already be selling at lower prices.
Data collection frequency in Pricer24:
Minimum data collection frequency: once a day for non‑dynamic categories
Normal data collection frequency: 3–7 times a day
In cases where a high update frequency is critical, we can update data hourly (and sometimes more often)
How Data Is Collected from Open Sources and How Parsers Work
All solutions for collecting and analyzing competitors’ prices use parsers — software that mimics the behavior of a human user. Parsers load and read web pages or other data sources, locating, identifying, and collecting the required information (for example, prices, product descriptions, and availability).
Automatically collecting open data is challenging because a parser does not perceive data the same way a human does. To collect data effectively, it is necessary to use different types of parsers and collection methods.
Types of Parsers in Pricer24
At Pricer24, we use different types of parsers to ensure high data quality:
Category parsers
Link parsers
Search parsers
File parsers
Category parsers collect information from an entire product category on a website. They enter the specified category, go through all pages in that category, and gather data on all products.
Link parsers are configured individually for a specific client. Their main task is to collect data from a list of URLs that the client wants to track. Pricer24 has a special module where the client can manually enter links. This approach allows them to control exactly which products or pages they want to monitor. It is convenient for working with selected SKUs — for example, when comparing alternative products.
File parsers are used when all data comes in a single dataset. This can be an integrated feed from your internal system or supplier prices in file formats. In this case, the data is transferred in bulk, and a single request is enough to collect it. We configure the file parser so that the system correctly reads the structure, navigates categories, and automatically extracts all required fields: name, price, availability, and so on.Important: Each parser belongs exclusively to one client, and no other client has access to its data. Our system reliably protects users’ information and your sensitive data.
Data Sources We Use for Price Analysis in Pricer24
Open sources: Websites of online stores, marketplaces, price aggregators, and mobile applications
Excel files: Price lists can be uploaded to the system manually or automatically via synchronization with external sources (FTP, Google Drive, etc.).
Suppliers’ B2B portals: If a client provides us with a login and password to their personal account on a supplier’s portal, we automate the collection of price lists, product availability, or other required data so they gain full control over pricing and procurement in one place: they can see both competitors’ and suppliers’ prices at the same time, enabling quick, optimal decisions without constantly switching between dozens of tabs.
Client’s internal systems: Pricer24 can integrate with the client’s internal accounting systems (for example, 1C, SAP, or other ERPs) to regularly receive data on warehouse stock, purchase prices, MSRP, and more.
In this way, open competitor data and the client’s internal data are consolidated in a single environment.
Types of Data We Collect
By default, each parser collects information about product prices and availability.
We can also collect data on promotions, credit terms, installment payment options, product specifications, and delivery conditions, as well as product tags and their ratings.
In addition, if needed, parsers can be configured to collect other data: volume, color, additional codes, images, descriptions, and more.
How We Control Data Timeliness
Each parser in our system has its own launch schedule, which determines exactly when the data is updated. For example, parsing may start at 07:00, 12:00, and 17:00 GMT.
For each launch, we set a Desired Parsing Time — the time window during which the system must complete data collection (for example, from 07:00 to 09:00) — and a Critical Parsing Time — the maximum allowable time for data collection. If the parser fails to update the data within the desired parsing time, the data receives an Outdated status.
If this happens frequently, or if the system exceeds the maximum allowable parsing time, our developers step in to fix the issue.
Very few providers on the market do this: usually, their parsers follow the same logic and operate the same way for all clients.
Why Collecting Open Data Accurately Is Difficult
Parsing competitors’ prices may seem like a simple task, since all information is open and available on websites. However, between “the data is publicly available” and “the data can be collected automatically” lies a gap filled with technical challenges. A parser does not see a web page the way a human does. It reads the code, and the code can be very different from how the site appears to people.
The parsing process can be roughly divided into two stages:
Bypassing protection and accessing the web page. Websites actively fight against bots using CAPTCHAs, human verification checks, IP address blocking, and dynamic changes to page structures. The parser must be taught to collect data despite these measures.
Finding exactly the data you need on the page. Even after gaining access to the page, locating specific data among thousands of lines of code is like finding a needle in a haystack. A product’s price might be labeled as “price,” “cost,” or “amount,” or it may even be hidden inside JavaScript code. Each website has a unique structure that may change regularly, and the parser must adapt to these changes.
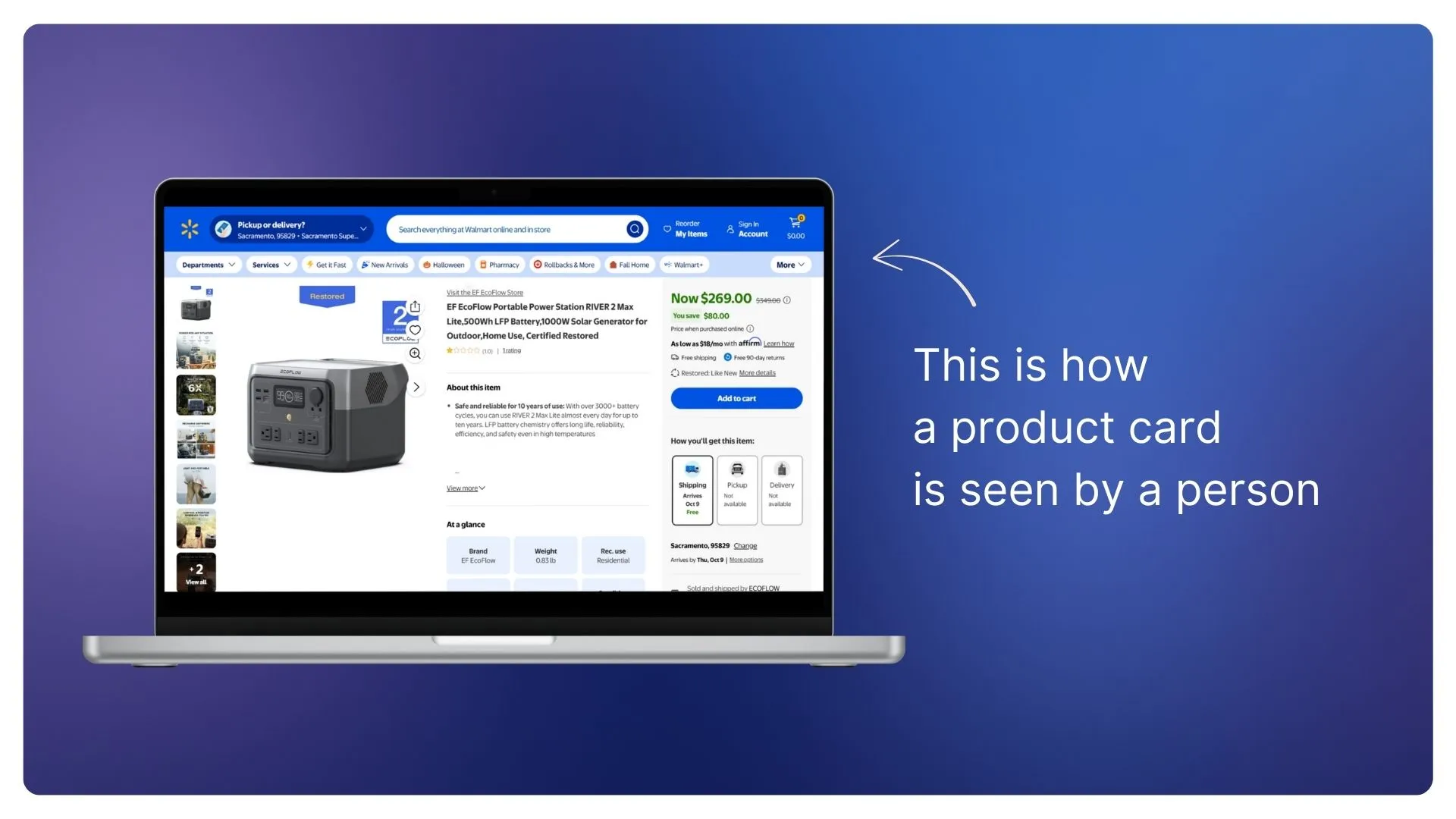
As an example, let’s consider a standard product page on the Walmart website.
When you, as a user, open this page, you see all the key details and specifications laid out neatly — product name, price, delivery options, and reviews.
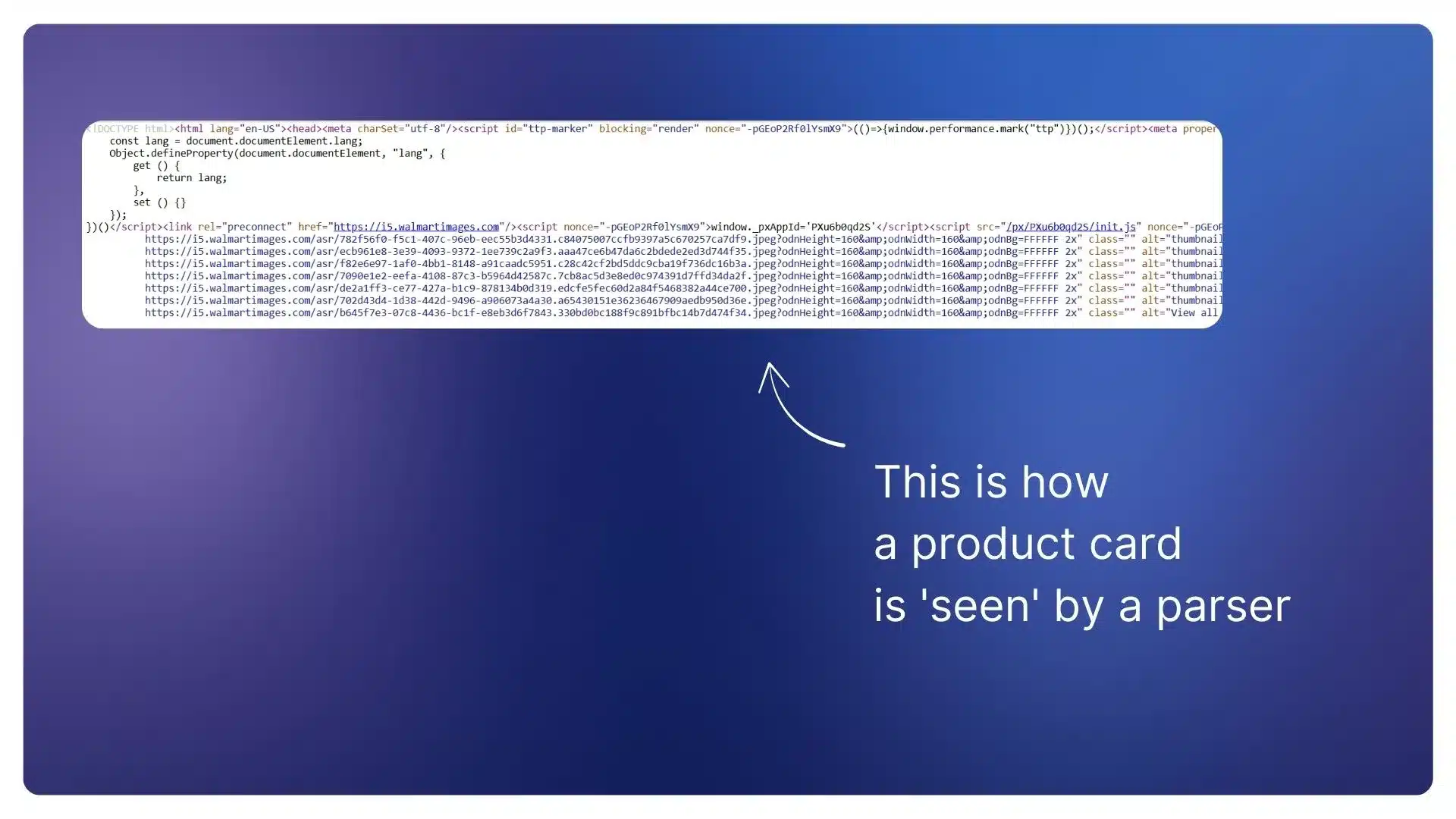
But the parser sees something entirely different — a block of HTML code like this:
If you look closely at this HTML code, you won’t find the product name, price, or rating anywhere. All the content you see as a user is, in fact, invisible to the parser.
This happens because many modern e‑commerce websites, in addition to static HTML (which search engines can read), display some content only after executing JavaScript.
In reality, when you view a product page, the browser first loads an empty HTML structure without the product name. Then, JavaScript makes additional requests to the server, retrieves the product data (name, price, description), and dynamically inserts it into the page in a user‑friendly layout.
How We Solve This Problem
We don’t need to download the entire page — the less data we load, the faster the process (later, we’ll explain why speed matters). Instead, we can design an algorithm that scans in a way that captures the maximum useful information without collecting unnecessary data, since that would increase parsing costs. We apply different strategies depending on the technical requirements.
The main challenge here is data structure instability. If a website changes field names (for example, “Pickup” → “Delivery”), the parser will still look for “Pickup,” fail to find it, and return an error.
These changes happen constantly and require ongoing parser adjustments. Structural changes, field name changes, and general website updates can break the parser for that specific site.
Here’s how we handle it:
We continuously monitor parser performance and receive instant alerts when something isn’t working as expected.
If a parser throws an error, we analyze exactly what changed on the site.
We rewrite the parser logic to match the new structure.
We test and relaunch the parser.
Maintaining high‑quality data requires continuous technical support, not a one‑time setup.
Every website is a unique puzzle. Over time, we’ve built an internal solution book that details which tools work best, how to bypass protection, and where certain fields are usually hidden.
Bottom line: What may seem like a simple task — copying data from a website — in reality demands the ongoing work of an entire development team to constantly adapt hundreds of parsers to changes in the data structures of different sources.
How Pricer24 stands out from other price analysis services:
We don’t rely on one‑size‑fits‑all solutions. Instead, we analyze each website individually to determine the most efficient way to extract the maximum amount of relevant information with the minimum number of requests. This means faster data collection and less load on target servers.
Our team has extensive experience and a deep understanding of the technologies used to build websites, their protection systems, and structural nuances. We select the most effective tools and methods for each specific site.
For every website, we customize our core solutions to ensure data is collected as quickly as possible, and at the promised frequency.
How Automated Product Matching Works on Competitors’ Websites
Once the parser has copied all data, the next step is identifying matching products.
It’s important to understand how price monitoring services find the exact products that correspond to yours among thousands of items in a competitor’s catalog, as this directly affects the discovery rate, i.e., the completeness of your data.
How do most price analysis services approach this task? The traditional method looks like this:
Take the client’s product catalog as the input.
Search for each product in the catalog on competitors’ websites.
Link the found product pages to the client’s items.
Collect prices from those links.
It sounds logical and straightforward. So where’s the problem?
In reality, a product you list as:
Leather Cat Collar WAUDOG Glamour with QR Passport, Plain, XXS, Width 9 mm, Length 22–30 cm, Blue (32482)
might be listed by a competitor as:
WAU DOG Glamour Cat Collar with QR Passport for Small Cats (Blue)
An automated system won’t match these items by name alone — and you won’t know the competitor is selling the same item.
Every competitor has their own naming conventions. To accurately match products across dozens of sites, you need to understand the naming rules for each category on each site.
Our Approach — From Broad to Specific
We take the opposite approach to most services.
When we start working with a new client, they provide us with their product catalog and a list of competitor websites to monitor. We then:
Agree on technical specifications — in which categories we should search for competing products.
Create a brand dictionary mapping competitor brand names to the brands in the client’s catalog.
Create a competitor product dictionary module.
Regularly collect all products in the required categories from competitor websites.
Match each collected competitor product to the client’s catalog — searching within one catalog is more efficient than searching across many (it’s easier to learn and navigate a single structure).
Base matches on the client’s catalog, not the competitor’s — this ensures consistency and accuracy.
For example, all products in the Laptop category (competitors might call it “Laptops,” “Notebooks,” or something else, as defined in the technical specification) from competitor sites go into our Dictionary. We then assign each competitor product to its corresponding item in the client’s catalog.
If the client’s assortment in a category is small — say, 3 laptops versus 3,000 at a competitor — collecting the entire competitor category is inefficient. In that case, we switch to the traditional search method used by most services to reduce costs.
Benefits This Approach Brings to Our Clients
Optimization & Accuracy. By reversing the matching process, we don’t need to learn the naming rules for every competitor’s website — only the naming logic of our client’s catalog. This ensures higher product matching accuracy and reduces the risk of missed items.
Daily New Product Detection. While other services may overlook new competitor products for months, we analyze competitor categories every single day and detect new items as soon as they appear. Once a new product is found, our system logs it in the Dictionary, our team searches for a match in the client’s catalog, and — if a match exists — links it immediately. This also allows us to maintain full monitoring even when competitors deliberately create duplicate listings with lower prices. As a result, the discovery rate remains consistently high.
Data Consistency. By continuously tracking changes to both your catalog and competitors’ websites, we keep your data accurate, up to date, and reliable at all times.
Finding Products with Confusing or Incomplete Names
We search for products using a combination of parameters at the same time, with the exact set of parameters defined by your technical requirements.
For example, when comparing laptops, we take into account SKUs / part numbers and product names. In cases where the match is not obvious, we take into account general technical specifications, such as amount of RAM, processor (CPU model, generation, frequency), graphics card type (GPU), storage capacity, and any other features that indicate the exact product configuration
For perfumes, additional attributes may include bottle volume; whether the product is a tester, an original, or a replica; and other category‑specific details.
This means that even if a product’s name differs from yours, we can still find the match.
How Product Matching Is Performed
One key factor determining the quality of any competitor price analytics service is the accuracy of product matching. This process directly impacts the accuracy of your data.
Common matching errors often occur due to:
Different product names across websites
Different ways of specifying product attributes
Changes to the actual product page URL, while the system continues comparing your product to an outdated link
Price analysis services typically use several approaches to product matching:
Automatic Matching — fast and scalable, but with a relatively high error rate
Manual Matching — can be highly accurate, but is resource‑intensive
AI‑Based Matching — a relatively new approach where product matching is performed using artificial intelligence models that attempt to understand the data and extract product names and descriptions
Product Matching at Pricer24
We use a combination of these three matching approaches in the most effective proportion for each client. We run multiple algorithms, each comparing products by different parameters — name, SKU, specifications, volume, category placement, and more — with the goal of finding as many accurate matches as possible between two products.
The results of each match then go through a reliability scoring system.
Matches flagged as questionable are sent for manual review.
If a product is matched incorrectly, a human reviewer records the error, ensuring the algorithm will not repeat it. As a result, the system becomes smarter with every check.
In addition, we have several layers of post‑matching verification, which ensures consistent data quality.
This approach allows us to achieve high accuracy even in complex cases — and to maintain stable, reliable data quality over time.
What Can Go Wrong? When Data Issues Cost Businesses Dearly
Based on our estimates, for most price analysis services, the discovery rate in complex categories rarely exceeds 50–60%, and in simpler categories it reaches 80–85%. The market average is around 70–75%. This means that a quarter to half of competitor prices may be missing from analysis.
Here are real‑world examples shared by clients who switched to Pricer24 after disappointing experiences with other platforms:
❌ Case 1: Incorrect Matching = Wrong Decisions
A system automatically matched a client’s laptop with an Intel i5 processor to a competitor’s laptop with an Intel i3 — same screen size, same brand, almost identical names. The category manager assumed the competitor had dropped their price and lowered theirs as well. In reality, the competitor was selling a lower-spec model.
Loss: –10% margin in just two weeks
❌ Case 2: Incomplete Data = Blind Spots
A client was receiving reports for the Smartwatches category. A competitor added a new product line with cheaper alternatives, but the category manager didn’t see them and continued selling the older model at an inflated price.
Loss: –15% sales in the category over two weeks until the issue was spotted manually
❌ Case 3: Outdated Data = Missed Opportunities
A competitor ran a 48‑hour promotion on popular smartphone models. However, the price data for that site was updated only once every three days. As a result, the discount never appeared in the report — and there was no competitive response.
Loss: missed timing for a price reaction, –23% sales (by SKU count) in a single week
Conclusion
Parsing and matching in automated price analytics are complex, multi‑layered processes. High‑quality data collection, processing, and preparation are always the result of meticulous work, accumulated expertise, and well‑established business processes within the analytics team.
Every business is unique, like a fingerprint. So, it’s only logical that your analytics tool should be tailored specifically to your company.
When choosing between a simpler universal solution and a customized price analytics system that adapts to your business, consider your specific objectives and, most importantly, the level of data quality you require. Your profitability and market competitiveness depend on it.
Pricer24 is the competitor price analytics tool that precisely meets your unique needs, delivering consistently high‑quality data you can rely on.
Request a demo to see how Pricer24 can meet your needs
Privacy policy
Your privacy is very important to us. We want your work on the Internet to be as pleasant and useful as possible, and you quite calmly used the broadest range of information, tools and opportunities that the Internet offers.
The personal information of the Members collected at the time of registration (or at any other time) is mainly used to prepare the Products or Services in accordance with your needs. Your information will not be transferred or sold to third parties. However, we may partially disclose personal information in special cases described in the “Consent with the mailing”
What data is collected on the site
At voluntary registration on reception of dispatch you send the Name and E-mail through the registration form.
What is the purpose of this data?
The name is used to contact you personally, and your e-mail for sending you mailings of newsletters, news, useful materials, commercial offers.
Your name and e-mail are not transferred to third parties, under any circumstances, except for cases related to the compliance with the requirements of the law.
You can refuse to receive mailing letters and remove your contact information from the database at any time by clicking on the unsubscribe link present in each letter.
How this data is used
With the help of these data, information on the actions of visitors on the site is collected in order to improve its content, improve the functionality of the site and, as a result, create high-quality content and services for visitors.
You can change your browser settings at any time so that the browser blocks all files or notifies you about sending these files. Note at the same time that some functions and services will not be able to work properly.
How this data is protected
To protect your personal information, we use a variety of administrative, management and technical security measures. Our Company adheres to various international control standards aimed at transactions with personal information, which include certain control measures to protect information collected on the Internet.
Our employees are trained to understand and follow these control measures, they are familiarized with our Privacy Notice, regulations and instructions.
Nevertheless, despite the fact that we are trying to protect your personal information, you too must take measures to protect it.
We strongly recommend that you take all possible precautions while on the Internet. The services and websites that we organize include measures to protect against leakage, unauthorized use and alteration of the information we control. Despite the fact that we are doing everything possible to ensure the integrity and security of our network and systems, we can not guarantee that our security measures will prevent illegal access to this information by hackers from outside organizations.
If this privacy policy is changed, you will be able to read about these changes on this page or, in special cases, receive a notification on your e-mail.